
客户项目中视频对象识别和检测
背景
除了最少量的标准元数据外,视频是一种不透明的媒介——一个信息“黑匣子”,其中数据缺乏模式、上下文或结构。
可能并非总是如此——面向移动设备的相机,例如 Apple 的 TrueDepth 和三星的 DepthVision,已经可以捕捉深度信息并将其直接传输到计算机视觉应用程序中,用于增强现实框架的开发、环境研究和许多其他可能的用途。
下一代最先进的移动捕获设备也可能具有实时语义分割功能,通过后处理图像到文本的解释将复杂的描述直接添加到素材元数据中,运行在新一波的移动神经网络芯片上。近期的标准视频片段甚至可能具有精细和更新的地理位置数据以及识别危险或暴力情况的能力,并在设备上触发适当的本地操作。
然而,除了隐私问题可能会阻碍支持 AI 的视频捕获系统的开发,从长远来看,升级到这些系统的成本仍然过高。因此,学术界和企业计算机视觉研究人员在过去 5 到 6 年的努力集中在从“哑”视频中提取有意义的数据上,重点是优化和轻量级的框架,用于视频片段中的自动数据收集和对象检测。
市场领先的免费和开源软件 (FOSS) 的可用性不断提高,从而加速了这一过程,从而产生了大量流行且有效的与平台无关的模块、库和存储库。许多这些 FOSS 解决方案也由主要的 SaaS/MLaaS 提供商实施,他们的产品可以长期集成到您的项目中,也可以在构思阶段用于快速原型设计。
视频对象检测的挑战
对象检测需要在图像上训练机器学习模型,例如循环神经网络 (RNN) 和卷积神经网络 (CNN),其中对象已被手动注释并与高级概念(例如“人脸”、“马”或“建筑”)。

在对数据进行训练之后,机器学习系统可以推断出新数据中是否存在类似的对象,在某些容错参数范围内,假设数据没有通过数据选择不当、学习率计划不合适而过度拟合,或其他可能使算法对“看不见的”输入(即与模型训练的数据相似但不完全相同的数据)无效的因素。
解决遮挡、重新捕获和运动模糊
视频对象检测的一种方法是将视频拆分为其组成帧,并对每一帧应用图像识别算法。然而,这放弃了从视频中推断时间信息的所有潜在好处。
例如,考虑遮挡和重新获取的挑战:如果视频对象识别框架识别出一个被路过的行人短暂遮挡的人,系统将需要一个时间视角来理解它已经“丢失”了主体,并优先重新获取。
主体可能丢失不仅是因为遮挡,而且是由于运动模糊,在相机移动或主体移动(或两者)对画面造成足够破坏,特征变得条纹或失焦的情况下,并且超出了拍摄的能力要识别的识别框架。

果系统只是解析帧,就不可能有这样的理解,因为每一帧都被视为一个完整的(和封闭的)情节。
除了这个考虑之外,与在每帧的基础上重复注册同一对象相比,视频对象检测框架在识别和跟踪对象方面的计算成本要低,因为从第 2 帧开始,系统大致知道它是什么在寻找。
离线视频对象检测
早期的时间一致性方法依赖于后处理识别,用户必须等待计算,并且系统获得足够的处理时间(和访问大量离线资源)以实现高水平的准确性。
例如,Seq-NMS(序列非最大抑制)是 2015 年 ImageNet 大规模视觉识别挑战赛的获奖者,它根据相邻帧的内容对重新获取对象的可能性进行评级,并从输入视频中的短序列进行分析.

这种方法评估感知对象的行为,而不是专注于它们的检测和识别,并且最适合作为其他基于离线视频的对象检测系统的辅助工具。
在过去的十年中出现了各种其他事后视频对象检测系统,包括一些尝试使用 3D 卷积网络的系统,这些网络可以同时分析许多图像,但不是以通常适用于实时视频开发的方式对象检测算法。
实时视频对象检测
当前的行业迫切需要转向实时检测系统的开发,离线框架有效地迁移到低延迟或零延迟检测系统的“数据集开发”角色。
由于循环神经网络以序列数据为中心,因此它们非常适合视频对象检测。2017 年,佐治亚理工学院 (GIT) 和谷歌研究院合作提供了一种基于 RNN 的视频对象检测方法,该方法在移动 CPU 上运行时推理速度高达每秒 15 帧。
光流
光流估计生成一个 2D 矢量场,表示一帧和相邻帧(之前或之后)之间的像素偏移
光流可以在一段视频片段中映射单个像素分组的进度,提供可以执行有用操作的指南。它已经在传统的高数据视频环境(例如视频编辑套件)中使用了很长时间,以提供可以应用过滤器的运动矢量,以及用于动画目的。
在视频对象识别方面,光流能够计算对象的不连续轨迹,因为它可以以旧方法(例如 Lucas-Kanade 方法)无法实现的方式计算中间路径。后者只考虑分组帧之间的恒定流,并不能在多组动作之间形成过度连接,即使这些分组可能代表同一事件,被遮挡和运动模糊等因素打断。
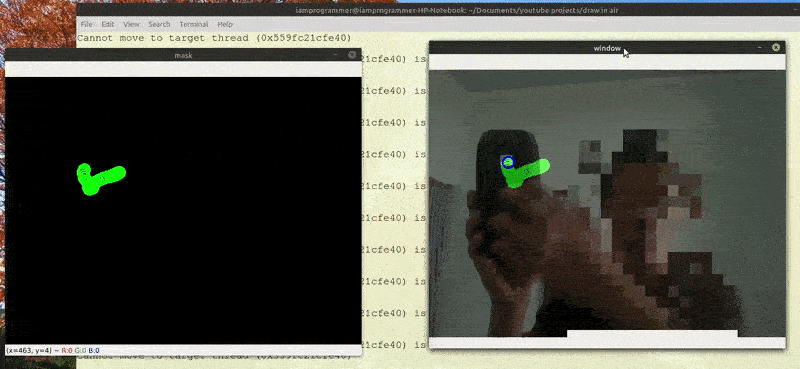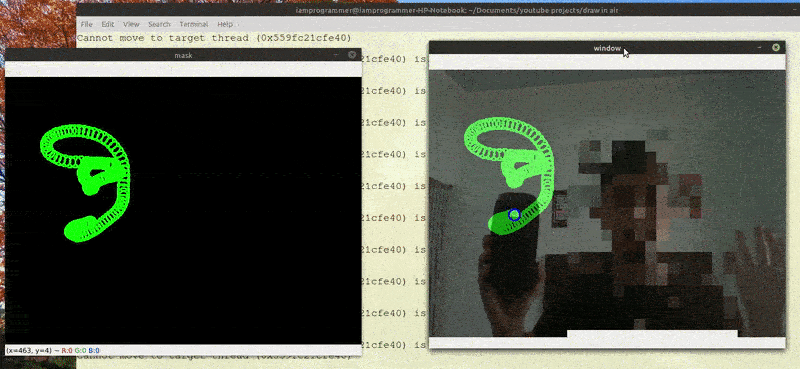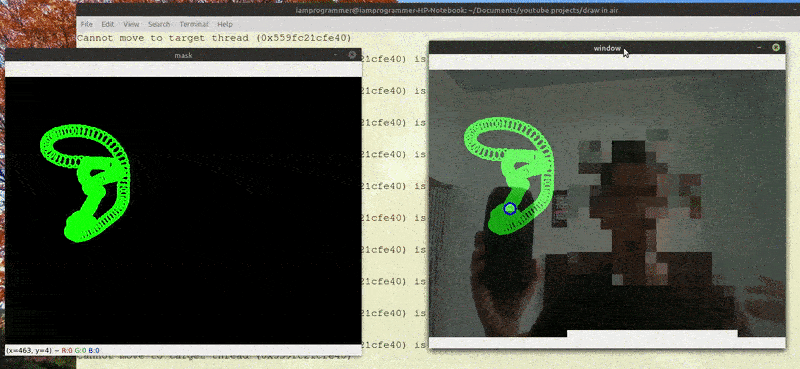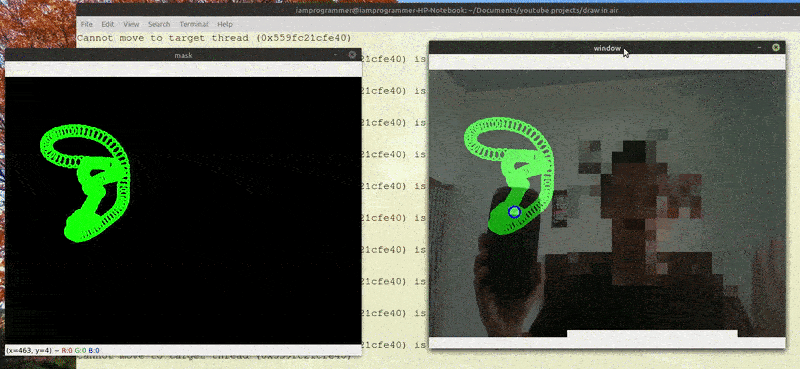
端到端的光流评估自然只能作为后处理任务。其结果随后可用于开发光流估计算法,该算法可应用于实时视频流。
许多新的基于光流的视频检测算法使用稀疏特征传播来生成连续流估计,并弥合偶然中断动作的差距。
此外,与光流相关的新数据集频繁出现,例如 MPI-Sintel 光流数据集,它具有扩展序列剪辑、运动模糊、未聚焦实例、大气失真、镜面反射、大运动以及许多其他具有挑战性的视频对象方面检测和识别。
开源视频对象检测框架和库
TensorFlow 对象检测 API
TensorFlow 对象检测 API (TOD API) 在计算机视觉领域可能是最广泛传播和流行的库的背景下提供 GPU 加速的视频对象检测。因此,它是包含在自定义视频对象检测项目中的显着竞争者。

TOD API 允许直接访问有用的框架库,例如 Faster R-CNN 和 Mask R-CNN(在 COCO 上),并且可以用作各种其他对象检测网络的前端,例如 YOLO(见下文)——不过其中许多将需要手动实施。
如果您的主要兴趣是敏捷和移动视频对象检测,TensorFlow 中心目前提供七个原生模型,无需进一步的挂钩或架构即可实现。更多种类的模型可用于桌面和服务器架构。
TOD API 的教程数据库包括使用网络摄像头检测对象的指导性演练,文档的标准和范围是该框架的显着优势。
YOLO:实时物体检测
You-Only-Look-Once (YOLO) 是一个独立维护的视频对象检测系统,可以以非常高的帧速率实时运行——公共限制为 45fps,报告的有用帧速率高达 155fps。YOLO 最初于 2015 年在 Facebook 的研究贡献下发布。

